
?
- Replication 和 partition 如何组合使用?
- 如何解决
并发问题? - 如何保证
consistency? - 如何提高
容错,应对如网络中断, latency spikes 问题
Summary
Replication 是什么?
Each node that stores a copy of the database is called a replica.
Replication 可以解决什么问题?
- High availability
- Disconnected operation: Allowing an application to continue working when there is a network interruption
- Latency: datacenter
- Scalability: 副本所提供的大量的
读能力
主要面临的问题
- 容错和并发: It requires carefully thinking about
concurrencyand about all the things that can go wrong, and dealing with the consequences of those faults. - 并发下的数据
一致性
Three main approaches to replication:
- Single-leader replication: 简单,不需要处理数据冲突
- Multi-leader replication
- Leaderless replication: 和 Multi-leader 容错更好,但是只能提供
very week consistency guarantees
如何解决容错和一致性?
Replication can be synchronous or asynchronous,which has a profound effect on the system behavior when there is a fault. 比如在 lag increases 和 servers fail 时如何处理?
一些 consistency model which are helpful for deciding how an application should behave under replication lag:
- Read-after-write consistency
- Monotonic reads
- Consistent prefix reads
Leaders and Followers(single-leader)
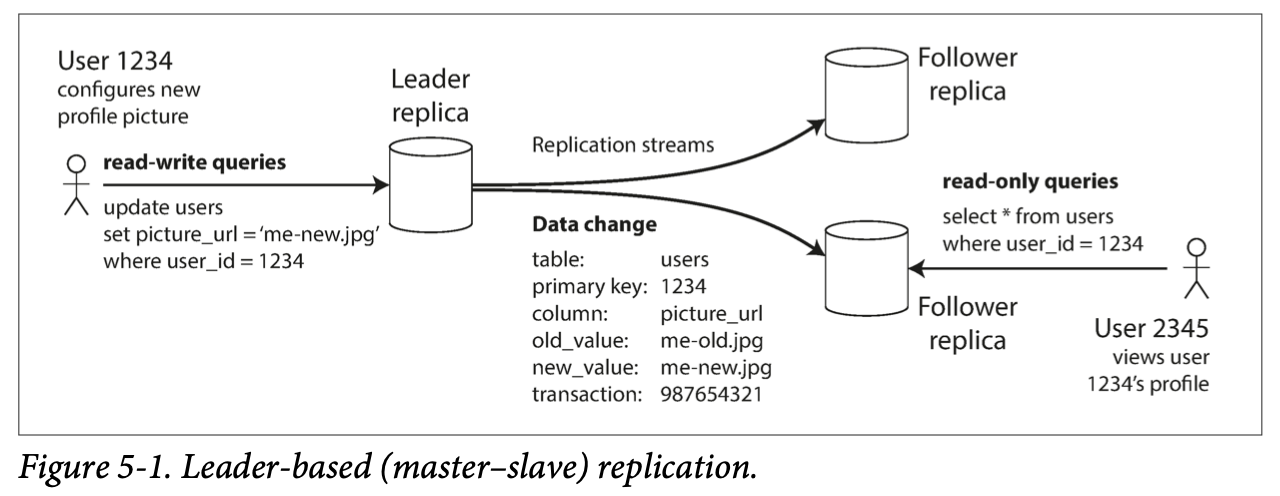
使用 leader-based replication(master–slave replication) 来解决 replication 写入问题的流程:
- 进行选主(elect leader)
- leader 写入时,会将数据以 replication log 或者 change stream 的形式发送给 followers, follower 更新本地 replication
- writes are only accepted on the leader (the followers are read-only from the client’s point of view).
This mode of replication is a built-in feature of many relational databases
Leader-based replication is not restricted to only databases, 如消息队列也会使用
Syncchronous Versus Asynchronous Replication
Synchronous
优势(保证数据一致性):
The follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader.
劣势(系统可用性差):
如果有 follower 无法响应(如遇到网络问题),那么 the write cannot be processed. The leader must block all writes and wait until the synchronous replica is available again.
所以所有 followers 都是同步是不现实的,一般使用如 semi-synchronous 方式,至少保证系统中一个 follower 是 sync 的,其他 follower 则是 async 的,This guarantees that you have an up-to-date copy of the data on at least two nodes
Completely Asynchronous
如何在并发场景下保证数据一致?
优势(可用性高): The leader can continue processing writes, even if all of its followers have fallen behind.
劣势:
写丢失: If the leader fails and is not recoverable, any writes that have not yet been replicated to followers are lost.不保证写入: A write is not guaranteed to be durable, even if it has been confirmed to the client
尽管如此,全异步还是被广泛使用,尤其在 there are many followers or if they are geo‐graphically distributed.
Setting Up New Followers(扩容时的一致性)
set up 新 follower 时,如何保证 the new follower has an accurate copy of the leader’s data?
- Take
a consistent snapshotof the leader’s database at some point in time—if possible, without taking a lock on the entire database. - Copy the snapshot to the new follower node.
- The follower connects to the leader and requests
all the data changes that have happened since the snapshotwas taken.
Handling Node Outages(容错)
其实就是如何保证 High Availability: Thus, our goal is to keep the system as a whole running despite individual node failures, and to keep the impact of a node outage as small as possible.
所以如何在处理机器不可用问题,以保证高可用?
Follower failure: Catch-up recovery
follower 本地保存 data chanage log(received from leader), 可以从 log 中进行恢复, 然后再从 leader 拿到停止时间内的 log 进行重建
the follower can connect to the leader and request all the data changes that occurred during the time when the follower was disconnected
Leader failure: Failover
如何处理?
- 重新选主
- followers 从新主获取数据
- client 和新 leader 交互
ha 机制:
Determining that the leader has failed
Choosing a new leader:The best candidate for leadership is usually the replica with the
most up-to-date data changes from the old leader(to minimize any data loss). Getting all the nodes to agree on a new leader is aconsensus problemReconfiguring the system to use the new leader:
The system needs to ensure that the old leader becomes a follower and recognizes the new leader.
一些问题:
如果使用异步 replication, new leader 和 old leader 之间可能存在 write 数据的差异, 此时 common solution 是 old leader 丢弃这些 writes.
丢弃写入可能会导致和其他外部存储系统数据不一致
split brain(有多个 node 认为自己是 leader): data is likely to be lost or corrupted; you can end up with both nodes being shut down
合理的 leader 失效 timeout 设置? load spike, network glitch 这些情况需要被综合考虑
node failures; unreliable networks; trade-offs around replica consistency, durability, availability and latency are in fact fundamental problems in distributed systems
Implementation of Replication Logs
the log is an append-only sequence of bytes containing all writes to the database
leader 将 log 写到本地,同时发送给 followers, follower 执行 log 来建立和 leader 相同的 replication
Statement-based replication
最简单的情况:
leader logs every write request(statement) that it executes and sends that statement log to its followers
缺点:
nondeterministic function(like now()) is likely to generate a different value on each replica.- they must be executed in exactly the
same orderon each replica, or else they may have a different effect. This can be limiting when there are multiple concurrently executing transactions. - Statements that have
side effects, unless the side effects are absolutely deterministic.
以上问题是可以绕过的
Write-ahead log(WAL) shipping
这是什么? 如何实现?
Describes the data on a very low level: a WAL contains details of which bytes were changed in which disk blocks。
因此难以适应数据存储格式的变化,但是可以解决 statement-based 的问题。
Logical(row-based) log replication
Logical log: 使用和 storage engine 不同的存储格式, 以便于解耦 log 和 storage engine
优点:
- 因为解耦所以 it can more easily be kept backward compatible, allowing the leader and the follower to run different versions of the database software, or even different storage engines.
- A logical log format is also easier for external applications to parse
Trigger-based replication
move replication up to the application layer.
An alternative is to use features that are available in many relational databases:
triggersand stored procedures.
A trigger lets you register custom application code that is automatically executed when a data change (write transaction) occurs in a database system. The trigger has the opportunity to log this change into a separate table, from which it can be read by an external process. That external process can then apply any necessary application logic and replicate the data change to another system.
it can nevertheless be useful due to its flexibility.
优点是灵活,缺点是 is more prone to bugs and limitations than the database’s built-in replication
Problems with Replication Lag
Replication Lag: the delay between a write happening on the leader and being reflected on a follower
In this
read-scaling architecture(Leader-based), this approach only realistically works with asynchronous replication,why?: synchronously 会导致系统不可用的几率变高 so a fully synchronous configuration would be very unreliable.如果使用异步系统,又会面临数据一致性问题。
所以本节主要介绍导致 lag 过长的场景和解决这些问题的方法.
Reading Your Own Writes
read-after-write consistency(read-your-writes consistency): 保证写入方写入后立即可见,但对其他 user 不进行保证
一些解决方案:
When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower, 但是当一个用户对系统进行大量读写的话,这个方式就会变得低效
client 端可以记录 write 的时间戳,向系统请求的时候带上时间戳,系统根据时间戳来判断当前 replica 是否可以提供服务,如果不行,就尝试其他的 replica, 否则一直等待直到收到数据写入,可以服务
If your replicas are distributed across multiple datacenters (for geographical proximity to users or for availability), there is additional complexity. Any request that needs to be served by the leader must be routed to the datacenter that contains the leader.
保证 Cross-device read-after-write consistency 的问题:
- remembering the timestamp of the user’s last update become more difficult
- If your replicas are distributed across different datacenters,there is no guarantee that connections from different devices will be routed to the same datacenter
Monotonic Reads(async 情况下)
对于 async followers 来说,由于 lag 不同,用户可能从不同的 follower 读到不同的数据,有些是过时的。
Monotonic reads 保证不读到过时的数据. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency.
If one user makes several reads in sequence, they will not see time go backward
One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica
Consistent Prefix Reads
consistent prefix reads: This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
This is a particular problem in partitioned (sharded) databases。in many distributed,databases, different partitions operate independently, so there is no global ordering of writes
一种解决方式事保证互相关联的写入被写入到同一个 partition.
Solutions for Replication Lag
在 eventually consisten system 中 lag 不断增长怎么办?
provide a stronger guarantee, such as read-after-write
但是 Eventual consistency 是不够的, db 需要 Transactions 来提供强一致性保证。
Multi-Leader Replication
可用性高,但是会面临 write conflicts 的问题,如何解决数据一致性问题?
是什么:
Multi-leader configuration (also known as master–master or active/active replication). In this setup, each leader simultaneously acts as a follower to the other leaders. 如 akka cluster
Use Cases for Multi-Leader Replication
不适应于创建 datacenter
Multi-datacenter operation

相比于 single-leader 方案的优势:
去中心化,write request 分散到各个 leader, which means the perceived performance may be better.
Tolerance of datacenter outages: 不需要重新选举 leader
Tolerance of network problems: A multi-leader configuration with
asynchronousreplication can usually tolerate network problems better: a temporary network interruption does not prevent writes being processed
缺点: the same data may be concurrently modified in two different datacenters, and those write conflicts must be resolved
一些使用 multi-leader 的系统:
- Tungsten Replicator for MySQL
- BDR for PostgreSQL
- GoldenGate for Oracle
Clients with offline operation
if you have an application that needs to continue to work while it is disconnected from the internet. 怎么解决?
比如在多个设备上使用同一个app, every device has a local database that acts as a leader (it accepts write requests), and there is an asynchronous multi-leader replication process (sync) between the replicas of your app on all of your devices
CouchDB is designed for this mode of operation
Collaborative editing
Real-time collaborative editing applications allow several people to edit a document simultaneously
会有啥问题? 怎么解决?
如果加锁的话就 is equivalent to single-leader replication with transactions on the leader.
如果想避免枷锁,就会带来 challenges of multi-leader replication, including requiring conflict resolution
Handling Write Conflicts
The biggest problem with multi-leader replication is that write conflicts can occur. 比如对同一份数据的修改请求到不同的 leader.
在 Multi-leader 情况下,只能异步的进行冲突检测,it may be too late to ask the user to resolve the conflict.
Conflict avoidance
avoid them: if the application can ensure that all writes for a particular record go through the same leader, then conflicts cannot occur.
Converging toward a consistent state
In a multi-leader configuration, there is no defined ordering of writes, so it’s not clear what the final value should be. 所以 all replicas must arrive at the same final value when all changes have been replicated.
4 种常用解决 write conflict 的方法:
- Give
each write a unique ID,比如last write wins方式:冲突时,选择最新的一条,但是这会有丢数据的风险 - Give
each replica a unique ID,ID越高则其对应的数据也有更高优先级,不过也意味着某些数据的无条件丢失。 - 合并:将冲突的值排序并连接起来, 如“你很漂亮/帅”
- Record the conflict in an explicit data structure that preserves all information, and write application code that
resolves the conflict at some later time
Custom conflict resolution logic
用户编写冲突处理逻辑, That code may be executed on write or on read:
On write: 修改数据时若检测到了冲突,则立即调用conflict handler处理。
On read: 存储所有有冲突的写入,读取时给出所有版本数据,用户自己进行数据选择。
Note that conflict resolution usually applies at the level of an individual row or document, not for an entire transaction
Automatic conflict resolutioncould make multi-leader data synchronization much simpler for applications to deal with.
Multi-Leader Replication Topologies
各个拓扑的介绍和优缺点?
replication topology: 如图,描述 writes request 在所有 nodes 间的传递轨迹。

Circular 和 star 的问题在于如果有 node down 掉, it can interrupt the flow of replication messages between other nodes. all-to-all 可以通过其他传递路径来避免这个问题.
all-to-all 缺点: 网络速度差异会导致 the result that some replication messages may “overtake” others
Leaderless Replication
Allowing any replica to directly accept writes from clients. 写的时候发送 write 到多个 replica, 多数成功则成功。读的时候也从多个 replica 读取,通过版本对比采纳最新的那份数据。
In some leaderless implementations, the client directly sends its writes to several replicas, while in others, a
coordinator node does this on behalf of the client. However, unlike a leader database, that coordinator does not enforce a particular ordering of writes
Leaderless replication is also suitable for multi-datacenter operation, since it is designed to
tolerate conflicting concurrent writes,network interruptions, andlatency spikes.
Writing to the Database When a Node Is Down
不存在 failover, client 直接忽略写失败的 replica, 写会同步请求多个 node,Version numbers are used to determine which value is newer
Read repair and anti-entropy
当 down 掉的机器恢复后,如何恢复缺失的数据呢,有 2 种常用方式:
Read repair: 读取的时候检测 stale value 并 recover, This approach works well for values that are frequently read.
Anti-entropy process: some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another
没有顺序如何保证写入的因果关系?
Quorums for reading and writing
设想:
n: replica 数量
w: 每个 write 都要保证 w 个节点写成功
r: 读取的时候至少从 r 个节点读取数据
所以只要 w + r > n, 这样读取的时候一定会读取到 w 中至少一个节点的数据,所以可以读到最新的数据。
A common choice is to make n an odd number (typically 3 or 5) and to set w = r = (n + 1) / 2 (rounded up). 可概以根据应用的读写情况对参数做调整.
The quorum condition, w + r > n, allows the system to tolerate unavailable nodes as follows:

Limitations of Quorum Consistency
即使 w + r > n, 也是无法完全保证数据强一致性的.
Stronger guarantees generally require transactions or consensus.
Sloppy Quorums and Hinted Handoff(草率的对话和暗示的交接)
leader-less dababase 可以提供 high availability and low latency, and that can tolerate occasional stale reads.
有些 quorums 并不能提供良好的 fault-toleratn,比如当发生网络split 时,一些 client 会离开集群,一些新的 client 可能会加入集群.此时如果保证 w 写入,但是 read 可能会读取到新加入的 client,从而无法拿到最新的数据.
Detecting Concurrent Writes
The problem is that events may arrive in a different order at different nodes, due to variable network delays and partial failures
当数据对写入顺序有要求(如聊微信)时,如何保证 eventually consisteny
Last write wins(discarding concurrent writes)
可以在多个冲突的写入中间选取最难 recent 的那个,如 LWW,其他的写入则被丢弃
The only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable, thus avoiding any concurrent updates to the same key.
Capturing the happens-before relationship
可以在 write request 中加入版本号,server 通过版本号来确定 2 个操作是不是并发(2个操作没有依赖关系)执行。
When a write includes the version number from a prior read, that tells us which previous state the write is based on.
Merging concurrently written values
As merging siblings in application code is complex and error-prone, there are some efforts to design data structures that can perform this merging automatically。

