
?
- Encoding 的含义是什么? 如何实现?
- Encoding 需要注意什么? 兼容性
- Encoding 的现状和发展趋势是什么?
- 如何保持 forward compatibility?
- Protocol Buffers, Thrift, and Avro 都是什么?
- REST, RPC, Actors, message queue 各自的概念和区别以及应用场景?
- RPC 相比于 REST 的优势在哪? 主要应用场景是什么?
- evolution of schemas over time?
Summary
data outlives code
本文介绍了多种 encoding(
turning data structures into bytes on the network or bytes on disk) 方式,并介绍了它们的实现细节和效率。涉及到 3 种 encoding formats:5
- Programming language–specific: 被语言限制并且对兼容性支持不好
- Textual formats: JSON, XML, and CSV: (1)兼容性取决于使用方式 (2)These formats are somewhat vague about datatypes
- Binary schema–driven formats: Thrift, Protocol Buffers, Avro
由于分布式环境下 many services need to support rolling upgrades, 所以 encoding 需要支持向前和向后兼容
encoding 的重要使用场景:
- Databases: 写入时 encode, 读取时 decode
- RPC and REST APIs: client encodes a request, the server decodes the request and encodes a response, and the client finally decodes the response
- Asynchronous message passing: encoded by the sender and decoded by the recipient
use
we must assume that different nodes are running the different versions of our application’s code.
Formats for Encoding Data
使用特定语言的序列化和反序列化类库存在跨语言,兼容性,安全性,性能等诸多问题,不建议使用。所以着重介绍 binary encoding。
JSON, XML, CSV are textual formats
适合作为数据交换 format, JSON,XML,CSV 的问题:
- There is a lot of
ambiguityaround the encoding of numbers - don’t support binary strings
- There is optional schema support for both XML and JSON,and thus quite complicated to learn and implement
- CSV does not have any schema
Binary encoding
在大数据量下使用 textual formats(更具可读性) 太过耗费空间,所以需要 binary encoding。
Some of these formats extend the set of datatypes, they need to include all the object field names within the encoded data.
Thrift and Protocol Buffers
2 者都 based on the same principle,即:
需要定义数据的 schema, 字段可以被标示为 optional 或者 required, 可以在 runtime 时对字段合法性进行 check, 同时使用 field tag 而非 field name 来压缩数据。
每条数据中包含 schema 信息,参见下图
Protocol Buffers
Thrift(
not good fit for Hadoop) 有 2 种编码方式: BinaryProtocol 和 CompactProtocol
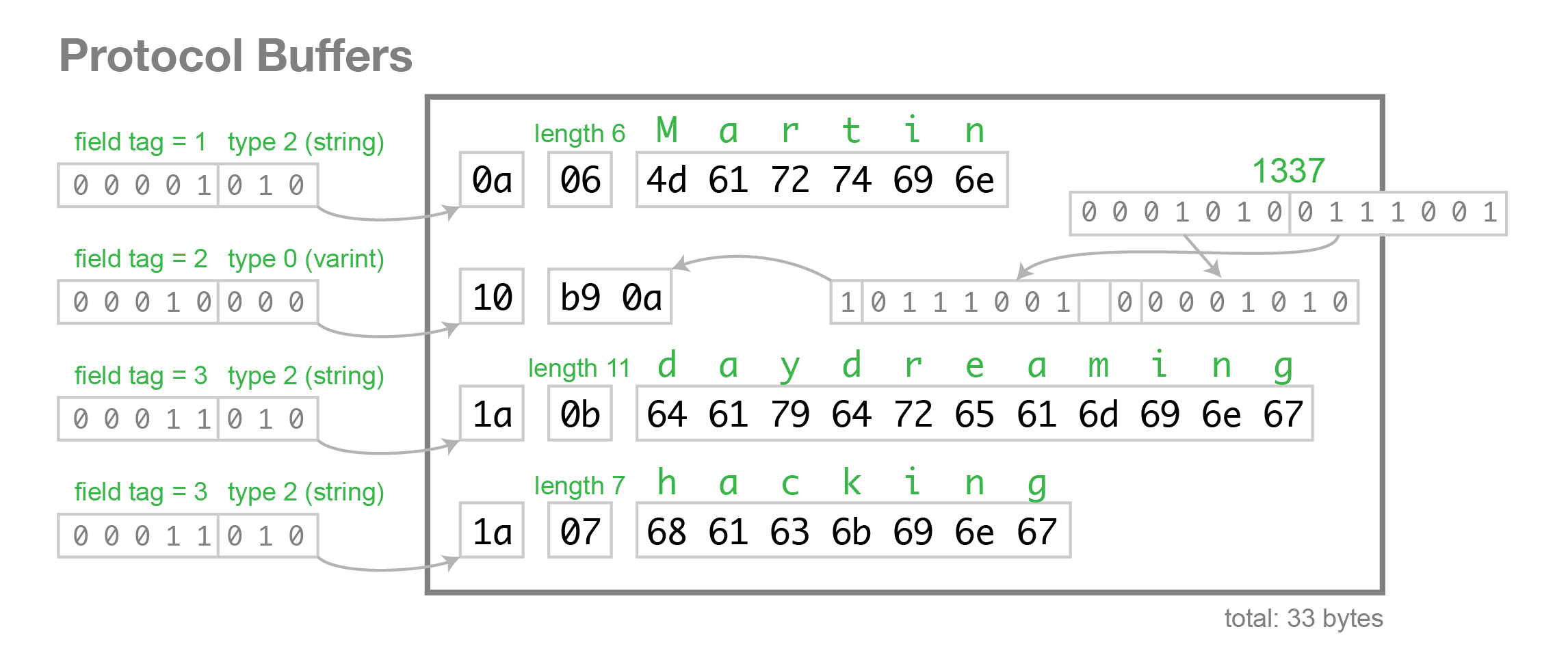
Field tags and schema evolution
How do Thrift and Protocol Buffers handle schema changes while keeping backward and forward compatibility?
Forward compatibility: 添加了新字段后,老的代码读取数据的时候忽略新的字段即可
Backward compatibility: As long as each field has a unique tag number, new code can always read old data
Removing a field is just like adding a field, with backward and forward compatibility concerns reversed.
Datatypes and schema evolution
数据类型改变时, 只能部分的支持兼容性。
数据类型改变时, there is a risk that values will lose precision or get truncated
Thrift 有 list 类型,不支持 single 和 list 的相互转换
protocol buffer 没有 list 类型,list 是 mutiple single, 所以可以支持 single 和 list 间的转换
Avro: hadoop 的子项目
Avro also uses a schema to specify the structure of the data being encoded.
encoding 数据中不包含 schema 信息,读取的时候 you go through the fields in the order that they appear in the schema and use the schema to tell you the datatype of each field.
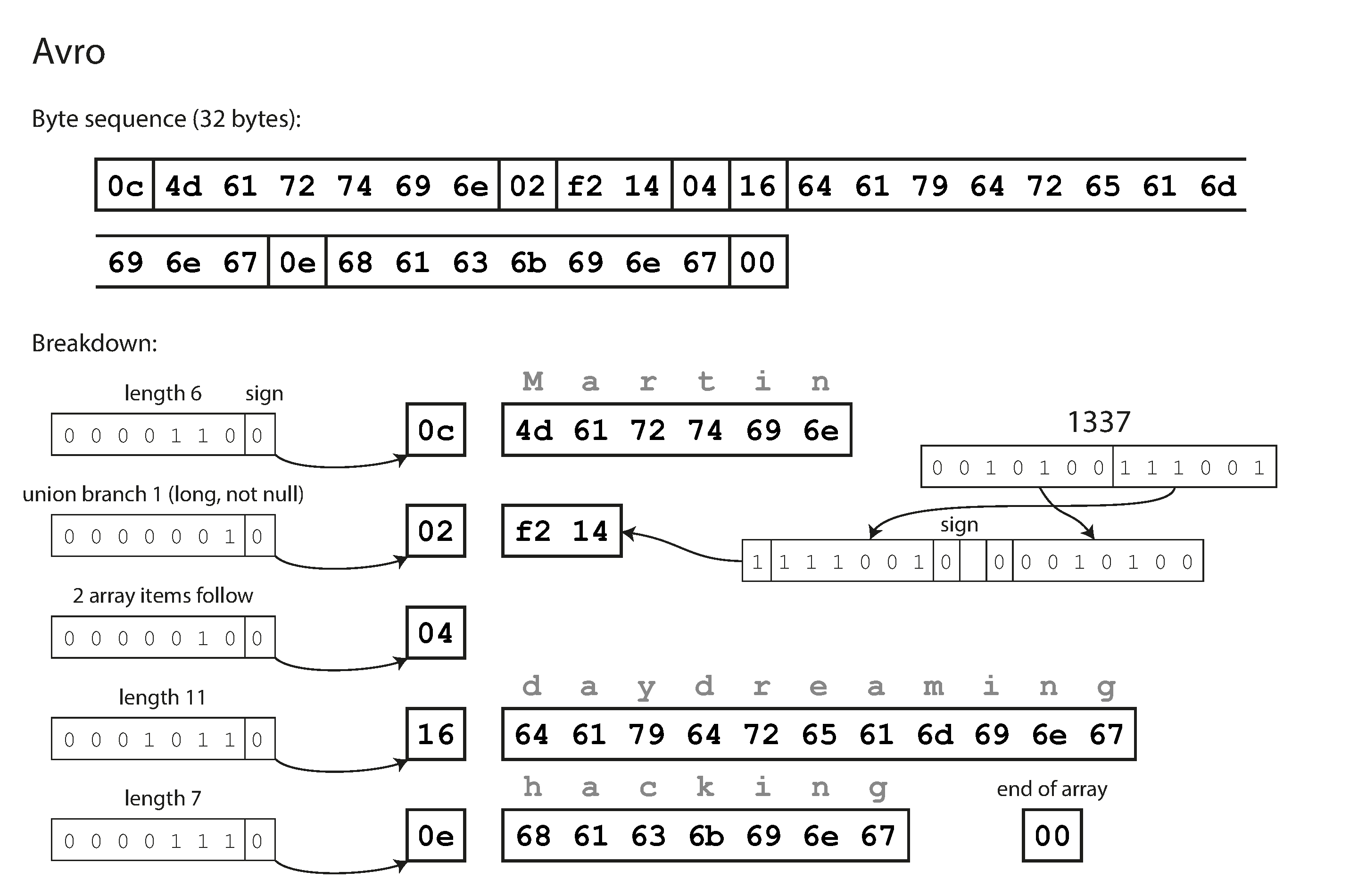
The writer’s schema and the reader’s schema
Writer's schema:encodes the data using whatever version of the schema it knows aboutReader’s schema:it is expecting the data to be in some schema
那怎么保证 shcema 变更导致的兼容性?
The key idea with Avro is that the writer’s schema and the reader’s schema don’t have to be the same—they only need to be compatible
Schema evolution rules
To maintain compatibility, you may only add or remove a field that has a default value
Avro doesn’t have optional and required markers in the same way as Protocol Buffers and Thrift do.
Changing the datatype of a field is possible, provided that Avro can convert the type.
But whats the writers schema
how does the reader know the writer’s schema with which a particular piece of data was encoded?
the writer of that file can just include the writer’s schema once at the beginning of the file
The simplest solution is to include a version number at the beginning of every encoded record, and to keep a list of schema versions in your database (类似 es)
网络通信时: they can negotiate the schema version on connection setup and then use that schema for the lifetime of the connection.
Dynamically generated schemas
Avro schema 中不包含 tag number, 所以 Avro is friendlier to dynamically generated schemas.
This kind of dynamically generated schema simply wasn’t a design goal of Thrift or Protocol Buffers, whereas it was for Avro.
Modes of Dataflow
There are many ways data can flow from one process to another, 看看 encoding 在其中的价值:
- Via databases
- Via service calls
- Via asynchronous message passing
Dataflow Through Databases
关系型中的数据写入时间差异很大,所以向前向后兼容都需要。
Dataflow Through Services: REST and RPC
SOA(microservices): This approach is often used to decompose a large application into smaller services by area of functionality.
In other words, we should expect old and new versions of servers and clients to be running at the same time, and so the data encoding used by servers and clients must be compatible across versions of the service API precisely what we’ve been talking about in this chapter.
Web services
REST: is not a protocol, but rather a design philosophy that builds upon the principles of HTTP. It emphasizes simple data formats, using URLs for identifying resources and using HTTP features for cache control, authentication, and content type negotiation.
SOAP: is an XML-based protocol for making network API requests. Although it is most commonly used over HTTP, it aims to be independent from HTTP and avoids using most HTTP features.
The problems with remote procedure calls(RPCs)
Although RPC seems convenient at first, the approach is fundamentally flawed:
- 网络问题不可控,必须自己做容错
- if you don’t get a response from the remote service, you have no way of knowing whether the request got through or not.
- 需要 deduplication 机制
- A network request is much slower than a function call, and its latency is also wildly variable
- 序列化和反序列化
- 不同语言之间的类型转换可能导致问题
Thus, you only need backward compatibility on requests, and forward compatibility on responses.
Message-Passing Dataflow(如: Akka)
A client’s request (usually called a message) is delivered to another process with low latency. message is not sent via a direct network connection, but goes via an intermediary called a message broker (also called a message queue or message-oriented middleware), which stores the message temporarily.
A sender normally doesn’t expect to receive a reply to its messages. This communication pattern is asynchronous: the sender doesn’t wait for the message to be delivered, but simply sends it and then forgets about it.
Message brokers
produecers -> topic -> consumers
Message brokers typically don’t enforce any particular data model
Distributed actor frameworks
Location transparency works better in the actor model than in RPC, because the actor model already assumes that messages may be lost.
Akka uses Java’s built-in serialization by default, which does not provide forward or backward compatibility

